
To whom it may concern, hello!, greetings, wassss upppppp!, and all other methods of saying hello on a blog… my name is Peter Latchem and I am a 4th year Chemist at the University of Southampton. I am taking part in a 6 month period of research, as part of my integrated masters, at New York University in the US. My blogs will mainly focus on life in the US, but I do believe that at least a few sciencey posts are obligated given it is the whole reason for this wonderful opportunity. This post is about the research area that I am now stepping into and would like to share with you all.
And so to my research area (most will be happy to know that this is in layman’s terms). Carbohydrates. Sugars. Saccharides. I am sure that at least some readers are suffering PBSD (post biology stress disorder) but whatever way you look at it, sugars are crucial to most, if not every form of life. Most sweet toothed readers will be aware of their No. 1 use and some may even be familiar with their crucial use as structural skeletons to a large array of life forms. But one of their most interesting usages is as border protection agents. No, the heat has not driven me insane, they are in fact crucial as ‘border protection’ agents to our bodies’ cells. Our cells are not dissimilar to the physical countries across the globe that form the larger world we live in. Each lives and thrives on their own, with their own strengths and weaknesses and, through cooperation, form part of a larger system. Countries cooperate to form the world (ignoring finer points of current politics) likewise cells cooperate to form our bodies. Just like the fine, though intimidating, customs agents around the world, our cells must control who and what comes in to their finely balanced country/cell. Sugars as parts of larger molecules play an indispensable role in this function. They act as recognition sites or bouncers, “if your name’s not down your not coming in” is the chime of the cell surface.
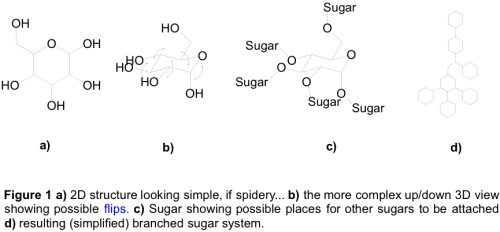
I hope that all readers have followed me thus far, and perhaps even can see now the importance of sugar based molecules as recognition sites (even if it is just through the analogy of border protection agents). Their importance links them to numerous possible disease states and hundreds of applications. It is therefore no surprise that they are a hot tip in the world of chemical biology and drug discovery. But as a business man may think, if they’re so good, why isn’t there already a wealth of understanding and drugs around them? This is because sugars are deceptively complex. Figure 1 shows the generic structure of one type of sugar. First it is drawn 2D and seems innocuous enough. But life is not 2D, and also included is how the same sugar looks in 3D. Note the ups and downs of the OH, the undulating hexagonal structure. Any of these OHs could be up, or down, the hexagon could be bent, pointing up, in one plane etc. this molecule is floppy! Now think about joining this sugar to another one, linked by an O as shown in Figure 1. Now we have two floppy molecules, that can be joined at ANY O position, what’s more why does it have to be the same sugar that we join to the same one?! These chains of sugars can keep being formed, how many combinations of hexagon shape/OH position/O linking/sugar composition can you think of? And when you consider that other molecules can be stuffed on, the hexagons can randomly open to straight lines or pentagons you begin to see the complexity that chemists and biologists are faced with.
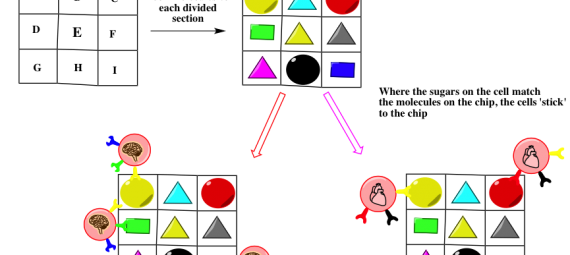
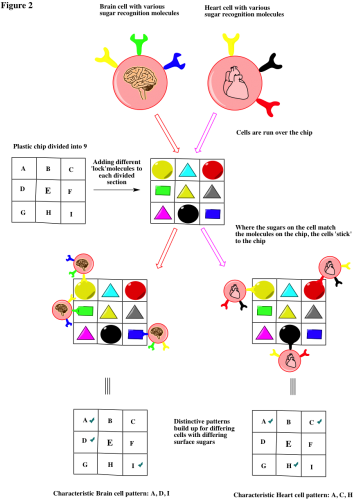
Deciphering a method of understanding such complex molecules could take a million years. Thankfully, we have a researcher who’s been doing just that. With an appropriate reference to Mother Nature et. al. we can find a way to analyse these oh so important sugars present on cell surfaces. Cell biology works on a touchy feely sense, cells and molecules interact only if the other ‘feels right’ in a lock and key like fashion. This means that biology has developed a molecule that is a ‘touchy feely’ molecule for every other molecule in nature. Imagine two cells, a brain cell and a heart cell. Each needs to protect their borders, so both have sugars on their surfaces to act like customs agents. But brain and heart cells provide different services, and so require different food/supplies in. This means that their ‘custom agent’ sugars must be different in order to specifically let in their own different supplies. What the Mahal laboratory has done is assemble a plastic chip, that has embedded on its surface 90 or so of the molecules that nature uses to ‘recognise’ sugars. This is shown in Figure 2. What we can do is pass a sample of cell, let us say the brain cells, over the chip. The sugars on the cell’s surface will probably not be ‘interested’ in most of the molecules on the chip and the cell will just keep wandering along. However if it finds a molecule that it ‘recognises’, the sugar will fit like a key in a lock, keeping the cell attached to the chip at the location of the molecule it fits. A cell will have several sugars on its surface and will bid to some molecules on the chip but not others. Let us say the brain cell will bind to the chip on sites A, D, and I. The heart cell, having different surface sugars may bind differently at A, C, and H. We have a way to differentiate cells with different sugars!! Figure 2 is an example with only 9 possible molecules on the chip for cells to interact with. The Mahal lab uses about 90, giving a very specific ‘fingerprint’ of binding, unique to each sugar/cell type. This technique is simple, can be automated by computer, is fast, cheap and requires very little sample to make a scan. BINGO!!! Biology does the tricky stuff with its millions of years of training, and we watch little blobs develop on squares and write them down, perfect.
This is a basic, if slightly lengthy, discussion of the first part of work carried out by the Mahal group. For those scientists (or brave laymen) amongst the readers I would recommend the reading of the following papers if you want to understand more about this fascinating and satisfying research.
- Pilobello, K.T.; Krishnamoorthy, L.; Slawek, D.; Mahal, L.K. Development of a Lectin Microarray for the Rapid Analysis of Protein Glycopatterns. ChemBioChem 2005, 6, 985-989.
- Hsu, K.-L.; Gildersleeve, J.C.; Mahal, L.K. A simple strategy for the creation of a recombinant lectin microarray, Mol. BioSystems, 2008, 4, 654-662.
Thank you for reading and I hope you now understand some more about the processes and knowledge used in this area of chemical biology! (apologies for any spelling, grammar, drawing, semantic mistakes, if you spot one give yourself a gold star or something…)